

داخلی
»مطالب کتابداری
»سخن هفته
لیزنا، دکتر اُکسانا اِل. زاوالینا، استادیار دانشکده اطلاعات دانشگاه تگزاس شمالی: حجم منابع اطلاعاتی جهان از رشد نمایانی برخوردار است؛ و در نتیجه، ما هم اکنون با اقیانوس عظیمی از اطلاعات روبرو هستیم که در آن یافتن قطره های کوچک اطلاعات بدون سازماندهی مناسب اگر غیر ممکن نگوییم، دشوار است. 
یکی از راه های سنتی سازماندهی اطلاعات، یعنی تکیه بر موضوع منابع اطلاعاتی، به ویژه در کتابخانه های دیجیتالی وسیع امروزی که میلیون ها فقره[1] و هزاران مجموعه مشتمل بر این فقره ها را گردآوری می کنند، تا به حال دستاوردهای زیادی را به همراه داشته است. اصطلاحات موضوع[2] یا ماده موضوعی[3] ناظر بر مفهومی هستند که یک منبع اطلاعاتی مانند کتاب، فیلم، عکس، یا وب سایت حول آن قرار دارد. برای چند دهه، دسترسی موضوعی یا دسترسی به اطلاعات مبتنی بر درون مایه موضوعی منبع اطلاعاتی یکی از مباحث محوری کتابداری بوده است. دسترسی موضوعی هم فرایند فهرستنویسی موضوعی یا به تعبیری عامتر تولید فراداده موضوعی[4] برای توصیف موضوع یک منبع اطلاعاتی توسط متخصصان اطلاع رسانی را در بر می گیرد و هم جستجو و بازیابی اطلاعات توسط کاربران سیستم های اطلاعاتی را. بر حسب اینکه بخش ارزش[5] در هر عنصر فراداده ای چطور جایدهی می شود، فراداده موضوعی را می توان به دو نوع مشخص تقسیم کرد:
از دهه 1990، هزاران مجموعه دیجیتال توسط مؤسسات میراث فرهنگی (کتابخانه ها، موزه ها، انجمن های تاریخی و آرشیوها) در سطح جهان تولید شده است. این امر از طریق دیجیتالی کردن منتخب هایی از موجودی های غنی آنها شامل مواد ارزشمند تاریخی حادث شده. شمار فزاینده ای از جوامع دیجیتال بزرگ-مقیاس[7] هم اکنون صدها مجموعه دیجیتال مانند حافظه آمریکایی[8]، کتابخانه اروپایی[9]، تاریخ گشا[10] و غیره را فراهم آورده اند. برای تسهیل دسترسی به مواد مجموعه ها، فراداده هایی برای توصیف نه تنها اشیاء منفرد بلکه تمامی مجموعه های دیجیتالی به عنوان یک کل جدایی ناپذیر تولید می شود (به شکل 1 رجوع کنید). اما آیا این فراداده با هدف کمک به کاربر برای یافتن، شناسایی، انتخاب و دستیابی به مجموعه های دیجیتال و اشیاء اطلاعاتی منفرد موجود در آنها متناسب است؟ برای یافتن پاسخ، اخیراً مطالعه ای انجام شد که به دنبال پاسخ به این سوال بود "نقش فراداده سطح مجموعه[11] در دسترسی موضوعی به کتابخانه های دیجیتالی ای که مجموعه های دیجیتال گوناگونی را جمع آوری می کنند چیست؟". برای انجام این پژوهش، سه روش تحقیق با یکدیگر ترکیب شدند:

شکل1 . مثالی از پیشینه فراداده سطح مجموعه در مجموعه دیجیتال
http://imlsdcc.grainger.uiuc.edu/history/collections/FullDisplay.asp?cid=81718
از نتایج این مطالعه چه چیزی می توانیم بیاموزیم؟
اول از همه، مشاهده و تحلیل داده های لاگ های تبادلی، همبستگی بسیار بالای فراداده سطح مجموعه با بازدیدها را به نسبت پنج به یک در میان صفحات پیشینه[12] های مجموعه و صفحات پیشینه های منتسب به هر فقره نشان می دهد. این بدان معناست که کاربران، معمولاً پیشینه های فراداده ای مجموعه را برای دسترسی به اطلاعات مجموعه های دیجیتالی ابزار مهمی می دانند.
حال، فراداده موضوعی به طور خاص چگونه است؟ با اینکه عناصر فراداده موضوعی سطح مجموعه چه با موضوع واژگان کنترل شده و چه با توصیف[13] زبان آزاد در هر سه کتابخانه دیجیتالی به کار برده شده است، اما کاربرد پوشش تاریخی[14]، پوشش جغرافیایی[15] و اشیاء[16] در این سه کتابخانه دیجیتال تمایزاتی دارد (شکل 2). با این حال، سطح کلی هماهنگی در کاربرد بیشتر عناصر فراداده ای موضوعی سطح مجموعه به طور قابل توجهی نسبت به مطالعاتی که کاربرد عناصر فراداده ای سطح فقره را مورد آزمون قرارداده اند بالاتر بود.
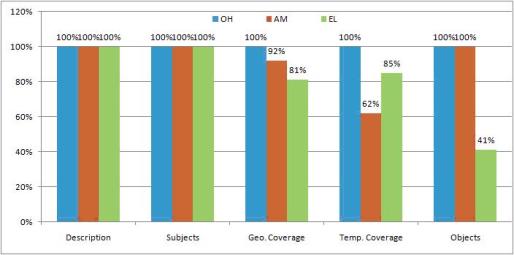
شکل 2. کاربرد عناصر فراداده ای موضوعی سطح مجموعه
اما این سوأل مطرح است که آیا پیشینه های فراداده ای سطح مجموعه به چندین عنصر فراداده ای موضوعی احتیاج دارند یا اینکه یک عنصر هم هدف دسترسی موضوعی را تأمین می نماید؟ این مطالعه با سه دلیل نشان می دهد که استفاده از عناصر بیشتر، بهتر است. نخست اینکه کاربران نوع پیشینه های فراداده ای مجموعه را در نظر می گیرند (شکل 1). این پیشینه ها مشتمل هستند بر چندین عنصر فراداده ای موضوعی که نسبت به روش - جایگزین به کار گرفته شده در چندین مجموعه – نمایش عنصر فراداده ای مجموعه با توصیف متن آزاد، مفیدتر است. دوم اینکه ارزش ها در عناصر فراداده ای موضوعی سطح مجموعه در موارد بسیاری مکمل یکدیگر هستند. بیشترین نقش مکمل بین عناصر موضوع و توصیف و فیلدهای پوشش جغرافیایی و توصیف وجود دارد؛ در حالیکه افزونگی بسیار کمی میان بخش ارزش عناصر فراداده ای مجموعه های مختلف مشاهده شده است. سوم آنکه تجزیه و تحلیل لاگ های تبادلی نشان می دهد که در جستجوی مجموعه بخش قابل توجهی از پیشینه های مجموعه بازیابی نمی شود. بنابراین، کاربران توانایی دسترسی به بسیاری از منابع دیجیتال را بدون وجود عناصر فراداده ای موضوعی مبتنی بر واژگان کنترل شده (پوشش زمانی، پوشش جغرافیایی، موضوعات و اشیاء) و فراداده متن آزاد (فیلد توصیف) نخواهند داشت.
تجزیه و تحلیل بخش ارزش عنصر فراداده ای توصیف در متن آزاد (شکل 3) نشان می دهد که جزییات مجموعه موضوعی - مانند انواع اشیاء در مجموعه دیجیتال، پوشش موضوعی، جغرافیایی و زمانی – به هماهنگ ترین شکل بازنمایی می شوند. کدامیک از دیگر انواع اطلاعات در مورد مجموعه دیجیتال، ارزش گنجاندن در عنصر فراداده ای توصیف را دارد؟ بهترین تجربیات نوظهور در ایجاد فراداده سطح مجموعه، همانطور که در این مطالعه مشاهده شد، گنجاندن عنوان مجموعه[17]، اندازه[18]، سیاست توسعه مجموعه[19]، اطلاعات حق معنوی مؤلف[20]، منشاء[21]، مخاطبان هدف[22]، راهبری و عملکرد[23]، زبان فقره های موجود در مجموعه[24]، بسامد رشد مجموعه[25]، مشارکت یا کمک موسسات[26]، منابع مالی[27]، نقاط قوت مجموعه (اهمیت، منحصربفرد بودن و جامعیت)[28]، و ایجادکننده فقره های مجموعه[29] را پیشنهاد می دهند.
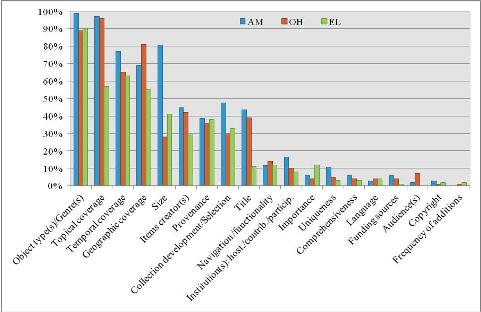
شکل 3. توزیع خواص مجموعه در عنصر توصیف در هر سه مجموعه مورد مطالعه
آیا این سیاهه درباره مجموعه های دیجیتالی که مخاطب اصلی – مورخ – بدان ها نیاز داشته باشد انواع اطلاعات را شامل می شود؟ پاسخ مثبت است. دانش پژوهان مشاهده شده، پیشینه های فراداده ای سطح مجموعه را به خاطر دربرداشتن اطلاعاتی درباره منشا، انواع اشیاء، موضوعات، پوشش جغرافیایی و پوشش زمانی ارزشمند می دانند.
این مطالعه از موجودیت های کتابشناختی الگوی ملزومات کارکردی پیشینه های کتابشناختی به عنوان چارچوب مفهومی و تحلیلی برای تجزیه و تحلیل سوالات تحقیق در سطح مجموعه استفاده کرد و دریافت که هم گروه سوم اف.آر.بی.آر. (مفهوم، شیء، رخداد و مکان) و هم موجودیت های گروه دوم اف.آر.بی.آر. (شخص و تنالگان) و نیز یکی از موجودیت های گروه اول - اثر منفرد - به صورت گسترده ای در میان جستجوها در مجموعه های دیجیتال به کار برده می شوند. جستجوی مجموعه های دیجیتال با نامی خاص نیز مشاهده شده است. هر چند موجودیت مجموعه به صراحت در الگوی اف.آر.بی.آر. ارائه نشده، اما مجموعه ها به وسیله رابطه "قسمتی است از" میان آثار موجود در سطوح مختلف با یکدیگر تطبیق داده می شوند. موجودیت های دیگری نیز ظهور یافته اند که برای درک دسترسی موضوعی در انبوهی از مجموعه های دیجیتال مهم هستند: طبقه(رده) اشخاص[30]، گروه قومی[31]. اکثریت جستجوهای سطح مجموعه که در این مطالعه تجزیه و تحلیل شده اند، درون گروه سوم موجودیت ها، یا همان موجودیت های موضوعی در الگوی اف.آر.بی.آر. مشتمل بر شیء، مفهوم و مکان قرار دارند.
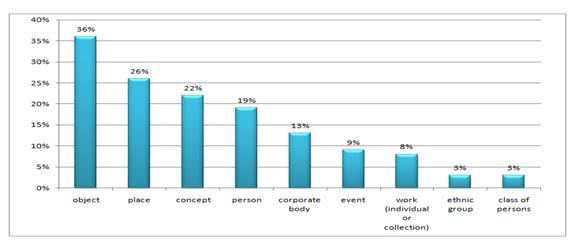
شکل 4. کاربر در سطح مجموعه توسط دسته بندی مبتنی بر اف.آر.بی.آر. جستجو می کند
این نتایج نشان می دهد که الگویی از دسترسی موضوعی سطح مجموعه را به عنوان کاربرد الگوی اف.آر.بی.آر در سطح مجموعه ای خاص می توان توسعه داد. علاوه بر موجودیت های موضوعی اف.آر.بی.آر. (اثر، شخص، تنالگان، مفهوم، شیء، رخداد و مکان)، این الگوی مبتنی بر اف.آر.بی.آر. می تواند شامل موجودیت های موضوعی مجموعه، طبقه اشخاص، و گروه قومی نیز باشد. برای تطبیق هر چه بیشتر چنین الگویی با زمینه استفاده در مجموعه های دیجیتالی می توان از یک عامل (کاربر مجموعه) و یک رابطه "جستجو می کند برای" نیز استفاده کرد (شکل 5).
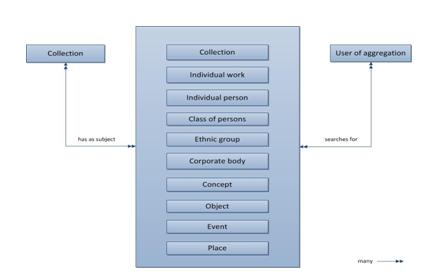
شکل 5. الگوی مبتنی بر اف.آر.بی.آر. از دسترسی موضوعی سطح مجموعه
نتایج این مطالعه اکتشافی، درک ارزش فراداده موضوعی سطح مجموعه را در میان کاربران مجموعه های دیجیتال گسترش می دهد و بعضی از بهترین تجربیات توصیف مجموعه های دیجیتال را به عنوان یک کل یکپارچه آشکار می سازد.
اما شماری پرسش مهیج برای تحقیقات آتی باقی می مانند که به قرار ذیل هستند:
اگر به این پرسش ها پاسخ دهیم، اطلاعاتی ضروری در اختیار خواهیم داشت تا مطمئن شویم که همه کاربران دسترسی موضوعی موفقی به کتابخانه های دیجیتال دارند.
[1] . Item
[2] . Subject
[3] . Subject Matter
[4] . Subject Metadata
[5] . Value
[6] . Free-Text
[7] . Large Scale
[8] . American Memory
[9] . The European Library
[10] . Opening History
[11] . Collection-Level Metadata
[12] . Record
[13] . Description
[14] . Temporal Coverage
[15] . Geographic Coverage
[16] . Objects
[17] . Collection Title
[18] . Size
[19] . Collection Development Policy
[20] . Copyright Information
[21] . Provenance
[22] . Intended Audience
[23] . Navigation and Functionality
[24] . Language of Items in Collection
[25] . Frequency of Additions to Collection
[26] . Participating or Contributing Institutions
[27] . Funding Sources
[28] . Collection Strengths (importance, uniqueness, and comprehensiveness),
[29] . Creators of Items in Collection
[30] . Class of Persons
[31] . Ethnic Group
«Collection-Level Metadata and its Role in Subject Access to Digital Libraries»
LISNA: Dr. Oksana L. Zavalina, Assistant Professor, College of Information, University of North Texas : The volume of the world’s information resources grows exponentially, and as a result, we are now facing an enormous information ocean where individual droplets of information are very hard – if not impossible – to access without proper information organization. One of the traditional ways to organize information – by the subject of an information resource – gains more and more prominence, especially in the vast digital libraries of today that aggregate millions of items and thousands of collections of these items. The terms subject or subject matter refer to what something (e.g., information resource such as a book, a movie, a photograph, or a website) is about. Subject access – or access to information based on the subject matter of information resource -- has been one of the central topics in librarianship for decades. Subject access encompasses both processes of subject cataloging (or, in broader terms, creation of subject metadata that describes subject matter of information resource) by information professionals and information seeking and retrieval by the users of information systems (Cochrane, 1985). Subject metadata can be subdivided into two distinct kinds based on how the values are encoded: controlled-vocabulary metadata which draws values from formally-maintained list of terms (e.g., Library of Congress Subject Headings, Art and Architecture Thesaurus, etc.), and free-text metadata which relies on natural language (e.g., abstract to journal paper).
Since 1990s, thousands of digital collections have been created by cultural heritage institutions – libraries, museums, historical societies, archives etc. – worldwide by digitizing selections from their rich holdings of historically valuable materials. A growing number of large-scale digital aggregations (e.g., American Memory, The European Library, Opening History, etc.) now bring together hundreds of these digital collections. To facilitate access to materials in aggregations, they are generating metadata to describe not only individual objects but entire digital collections as integral wholes (cf. Figure 1). But does this metadata fit its purpose of helping the user of aggregations to find, identify, select, and obtain (Functional Requirements for Bibliographic Records, 2008) access to digital collections and individual information objects in them? To find this out, the exploratory study was recently conducted which sought the answer to the question “What is the role of collection-level metadata in subject access to digital libraries that aggregate multiple digital collections?” and combined three research methods:
comparative content analysis of collection-level metadata in three large-scale cultural heritage digital aggregations in the United States and European Union: Opening History (OH), American Memory (AM), and The European Library (EL)
transaction log analysis of user interactions with Opening History (OH), and
interview and observation of academic historians interacting with two US-based digital aggregations: Opening History (OH) and American Memory (AM).
Figure 1. Example of collection-level metadata record in digital aggregation: a snapshot
(http://imlsdcc.grainger.uiuc.edu/history/collections/FullDisplay.asp?cid=81718)
What can we learn from the results of this exploratory study?
First of all, both observation and transaction log data demonstrates a high level of engagement with collection-level metadata, with the total page views for collection records almost 5 times greater than page views for item records. That means that the users perceive collection metadata records in general an important tool in access to information in digital aggregations.
Now, what about the subject metadata in particular? Although controlled-vocabulary Subject and free-text Description collection-level subject metadata elements are consistently applied in all three digital libraries, application of Temporal Coverage, Geographic Coverage, and Objects varied across the three digital libraries (Figure 2). However, overall level of consistency of application was considerably higher for most of the collection-level subject metadata elements than in the studies that examined consistency of application of item-level metadata elements.
Figure 2. Application of collection-level subject metadata elements
But do the collection-level metadata records need multiple subject metadata elements or can one element fit the purpose of subject access? This study shows that more is better, for three reasons. Firstly, the users consider the type of collection metadata records (Figure 1) that includes multiple subject metadata elements more useful than the alternative approach taken by many aggregations, which displays only the free-text Description collection metadata element. Secondly, the values in different collection-level subject metadata elements are in many cases mutually complementary. Most complementarity is observed between Description and Subjects elements and between Description and Geographic Coverage fields, while very little redundancy between the values in different collection metadata elements was observed. Thirdly, transaction log analysis shows that collection search would not retrieve a significant proportion of collection records and therefore users would not be able to access many digital without controlled-vocabulary subject metadata elements (Temporal Coverage, Geographic Coverage, Subjects, and Objects), and free-text metadata (the Description field).
Analysis of in free-text Description metadata element values shows us (Figure 3) that subject-specific collection properties -- types and genres of objects in a digital collection, topical, geographic and temporal coverage -- are the most consistently represented. What other kinds of information about a digital collection are worth of inclusion into Description metadata element? The emerging best practices in collection-level metadata creation, as observed in this study, suggest also including collection title, size, collection development policy, copyright information, provenance, intended audience, navigation and functionality, language of items in collection, frequency of additions to collection, participating or contributing institutions, funding sources, collection strengths (importance, uniqueness, and comprehensiveness), and creators of items in collection.
Figure 3. Distribution of collection properties in Description elements in three aggregations
Does this list include the kinds of information about digital collections that the target audience – in the case of these three aggregations of cultural heritage digital collections, history researchers – needs? The answer is yes: scholars who were observed viewing collection-level metadata records valued information on provenance, collection size, types of objects, subjects, geographic coverage, and temporal coverage.
This study used the bibliographic entities from the Functional Requirements to Bibliographic Records model as a conceptual and analytic framework to analyze collection-level search queries and found that both FRBR Group 3 (concept, object, event, and place) and Group 2 entities (person, and corporate body), as well as one of the Group 1 entities — individual work — are widely represented among the searches in digital aggregation. The searches for specific named digital collections were also observed. Although collection entity is not explicitly represented in the FRBR model, collections are accommodated by “is part of” relation between works of different levels. Additional entities emerged that are important for understanding of subject access in aggregations of digital collections: class of persons, and ethnic group. Majority of collection search queries analyzed in this study fall within Group 3 of entities, or subject entities, in FRBR model: object, concept, and place (Figure 4).
Figure 4. Collection-level user searches by FRBR-based search category
These results suggest that a model of collection-level subject access can be developed as a specific collection-level application of the FRBR model. In addition to FRBR subject entities (work, person, corporate body, concept, object, event, and place), this FRBR-based model can include collection, class of persons, and ethnic group subject entities. For such a model to further align with the context of use in digital aggregations, it can also include an agent (user of aggregation) and a “searches for” relationship (Figure 5).
Figure 5. FRBR-based model of collection-level subject access
The results of this exploratory study extend the understanding of the value of collection-level subject metadata for the users of digital aggregations and reveal some best practices in describing digital collections as integrated wholes.
But a number of exciting questions remain for the future research, including:
How differently is collection-level metadata applied in digital aggregations of different scope (e.g., national, regional, state) and focus (e.g., social sciences, humanities, sciences)?
What is the difference in users’ information seeking behavior in digital aggregations of different scope and focus?
How does collection-level metadata application and users’ information seeking behavior differ between digital aggregations in various counties and regions of the world?
If we answer these questions, we would have the information necessary to make sure that subject access in digital libraries is successful for every user.
زاوالینا، اُکسانا ال. « فراداده سطح مجموعه و نقش آن در دسترسی موضوعی به کتابخانه های دیجیتال». ترجمه ملیحه دُرخوش. پایگاه تحلیلی خبری لیزنا. سخن هفته شماره 61. 19 دی 1390.
Zavalina, Oksana L. « Collection-Level Metadata and its Role in Subject Access to Digital Libraries». Translated by Malihe Dorkhosh. Library and Information Science News Agency (LISNA). 61st Weekly Note. February 8, 2012










۱. از توهین به افراد، قومیتها و نژادها خودداری کرده و از تمسخر دیگران بپرهیزید و از اتهامزنی به دیگران خودداری نمائید.
۲.از آنجا که پیامها با نام شما منتشر خواهد شد، بهتر است با ارسال نام واقعی و ایمیل خود لیزنا را در شکل دهی بهتر بحث یاری نمایید.
۳. از به کار بردن نام افراد (حقیقی یا حقوقی)، سازمانها، نهادهای عمومی و خصوصی خودداری فرمائید.
۴. از ارسال پیام های تکراری که دیگر مخاطبان آن را ارسال کرده اند خودداری نمائید.
۵. حتی الامکان از ارسال مطالب با زبانی غیر از فارسی خودداری نمائید.